
단순히 ~가 아니라 ~입니다,
~는 ~한 ~가 아니었습니다. 대신, ~
명확했습니다,
분명했습니다,
~보다는 ~입니다,
피드백 루프,
깊이 공감,
~는 ~한 [명사]입니다,
...
요즘 포스팅들에서 유독 많아진 말투다. 최근에 읽은 한 아티클은 (내용은 정말 좋았다) '아니라'만 10번 사용했다. '아니었습니다'와 '아닌'까지 합치면 20번이나 되었다.


러쉬의 LTV상승 마케팅 전략에 대해 쓴 글을 Chat GPT에게 주고 블로그 글로 다듬어보라고 했다.
[브랜딩/마케팅] 인스타그램을 포기했지만 아무것도 포기하지 않은, LUSH의 가치 마케팅 "다른 곳
힙한 마케팅의 비밀!2021년 11월, 러쉬는 공식 홈페이지에 ‘러쉬 공식 성명문: 러쉬 소셜 미디어(페이스북, 인스타그램, 틱톡, 왓츠앱, 스냅챗) 중단 선언[🔗]’이라는 성명문을 업로드했습니다.
urdle.tistory.com
그랬더니 첫 문단:
러쉬는 최근 성명문을 통해
**“소셜 미디어 플랫폼이 사용자에게 더 안전한 환경을 제공한다는 것이 확인될 때까지 사용을 중단하겠다”**고 밝혔습니다.
이 선언은 단순한 채널 운영 변경이 아니라, 일종의 보이콧에 가까운 캠페인처럼 보입니다.
챗 지피티, 제미나이, 노션AI 등 다양한 AI를 활용하다 보니 AI 말투가 눈에 익었다. 대충 어떤 AI를 활용했는지도 감이 올 때가 있다. 사람이 글 쓰는 속도와 AI가 글 쓰는 속도가 다르니 이젠 AI가 작성한 글들이 엄청나게 많아졌고, 이 글들을 AI가 또 학습해서 AI의 말투는 되먹임(피드백)되어 점점 더 굳어지는 것 같기도 하다.
아무튼 간에 나는 거대언어모델들이 자꾸만 비슷한 말들을 쓰는 이유가 궁금했고, 특히나 역접과 함께 '정의내리기'를 남발하는 이유가 너무나도 궁금했다. (OpenAI 포럼과 레딧에도 나랑 비슷한 생각을 한 사람들의 글이 올라오고 있었다.)

그래서 리서치를 좀 해봤다. 사실 너무나 빨리 변화하는 분야이고 LLM의 버전별로 화법 또한 달라질 수 있기에 이 현상을 정확히 설명하는 연구는 없었다... 다만 부연적으로 설명할 수 있는 것들은 찾았고 그 내용을 적어본다.
사람들이 많이 씀
가장 그럴듯한 이유다. 애초에 학습되지 않았다면 자주 등장할 리가 없다. 순차 예측 모델이기에 '있을 법하다'의 기준은 통계적으로 산출한다.
돌이켜보면 인간은 어떤 개념을 정확하게 말하기 위해 대조를 사용하곤 했다. 애초에 인간도 자주 쓰던 말이라는 거다.
이런 역접구조는 특히 사람들의 흔한 오해를 교정하고 적확한 개념을 설명하기 위해 주로 사용하는 어구이기 때문에 정보성 글에서 많이 관찰된다. 거기다, 수많은 사람들이 질문에 대한 답을 얻으려고 LLM을 사용하다 보니 저런 역접의 문장구조가 많이 생산되고, 실제로 개념을 더 뾰족하게 만드는 문구이기 때문에 이를 거르지 않고 자신의 블로그 글에도 그대로 집어넣는다.
그러면 LLM은 그러한 데이터를 또 학습하고, 이런 문구를 사용하는 경향이 강화되는 것이다. 인간도 일상생활에서 AI의 말하기 패턴을 학습하니, 그 효과는 더 컸으면 컸지 작다고 할 수 없다.
이런 기사도 있다.
챗GPT가 사람들 말투도 바꾼다…일상 대화에서 급증한 ‘이 단어’
챗GPT가 사람들 말투도 바꾼다일상 대화에서 급증한 이 단어
www.chosun.com
사람들이 선호함
LLM은 RLHF를 통해 사람들의 반응을 학습해 반영한다. LLM이 많이 사용한다는 것은 사람들이 긍정 피드백을 많이 준 패턴이라는 얘기다.
나름대로 분석해보자면, 단순히 대화를 하려고 LLM을 이용하는 사람보다는 정보를 얻으려고 LLM을 이용하는 사람이 훨씬 많으니, 오개념을 다듬어주거나 (LLM의 설명이 맞든 틀리든) 더 구체적인 개념을 제시하는 화법에 사람들은 긍정적으로 반응할 것 같다. 그런 화법이 인간의 불안감을 없애주기 때문이다.
이어붙이다가 back하기보다 어쨌든 문장을 마무리 짓는 게 효율적
사람들은 LLM이 '생각'을 할 줄 안다고 믿기도 한다. 하지만 LLM은 인간처럼 '사고'하지 않는다.
챗 지피티와 제미나이에 대해 궁금해하는 지인들에게 나는 이것들이 '엄청 긴 자동완성'이라고 설명한다.
LLM의 알고리즘은 다양하지만 기본 원리는 비슷하다. '뒤에 올 만한 단어를 계속 이어붙이는 것'.

자동완성으로 다음에 올 단어 후보가 수천만 개 있다면 그 중에서 확률이 높은 것들이 있을 테고, 그 주요 후보들을 랜덤하게 또는 일정한 규칙에 따라 계속 골라 나가며 문장을 완성한다.
(사실 인간의 말하기 또한 자동완성이다. "아무래도 좀" 뒤에 "그렇지"를 자연스럽게 상상하거나 말하는 것처럼.
차이점이 있다면 인간은 말하고자 하는 바가 머릿속에 있고 그것을 표현하려고 언어라는 소통수단을 사용한다면,
LLM은 언어를 흉내냄으로써 사고를 흉내낸다는 거다.)
그런데, 이미 이어붙인 말을 삭제하고 다시 이어나가는 것은 비효율적이다.

위의 사례에서 LLM이 '폭신폭신한' 뒤에 '느낌이'를 이어붙인 상태였다면, 1,2,3번과 같이 이어붙였을 것이다. 4번 '폭신폭신한 느낌이... 을! 맛보여드리고 싶어서'는 인간의 화법이다. 물론 저렇게 말하는 사람은 흔치 않겠지만 '폭신폭신한 느낌이... 아, 느낌을 맛보여드리고 싶어서'라고 말하는 사람은 정말 많을 거다. 말했던 것을 무르고 다시 이어 말하는 것은 원래 말하고자 하는 바가 확실했던 화자, '생각'하는 화자, 즉 인간의 화법이다.
하지만 LLM은 일단 이어붙인 것을 무르려고 하지 않는다. 생각을 하는 게 아니기 때문이다. 다만, 알고리즘으로 앞에서 말했던 문자열을 기억하고 있기 때문에 '이어질 법한' 맥락 자체는 가지고 있다. 따라서 만약 이은 내용이 앞단의 내용과 어울리지 않는다면 그냥 문장으로 어떻게든 마무리하며 의미를 전환해버린다.
그런데 '~가 아니라'라는 말 자체는 너무나도 많이 쓰이는 어구여서 순차 예측 모델이 갖고 있는 '뒤에 올 법한' 말들의 풀에서 '뒤에 올 확률'을 높게 평가받는다. 즉 우선순위가 높고, 자주 등장한다. 추측컨대, 그런 경우, '~가 아니라'라는 역접을 이미 붙여버렸기 때문에 더 강한 정의를 내리며 문장을 마무리하게 되는 것으로 보인다. 왜냐, 1) '~가 아니라' 뒤에 오는 말은 대부분 앞 부분을 더 구체화하거나 반전시키는 단정적 어조로 끝맺음되니까. 2) 앞단에서 말한 내용에서 벗어나면 안 되니까.
더하여 참고할 만한 자료:
- 과학 연구에서 'delve', 'intricate', 'underscore'가 자주 등장하기 시작했고 이것이 LLM 때문일 것이라고 추측하는 따끈따끈한 연구. 큰 학회에서 발표된 내용이어도 프로시딩이라 공신력은 높지 않지만 아무래도 분야가 분야다 보니 이렇게 빠르게 연구를 내놓는 경우가 많은 듯... 학술지 통과에 걸리는 몇 개월 동안 모델이 업데이트되면 또 결과가 달라지니까. 암튼 참고해볼 만하다. Juzek, T. S., & Ward, Z. B. (2025, January). Why does ChatGPT “Delve” so much? Exploring the sources of lexical overrepresentation in Large Language Models. In Proceedings of the 31st international conference on computational linguistics (pp. 6397-6411). https://arxiv.org/pdf/2412.11385v1
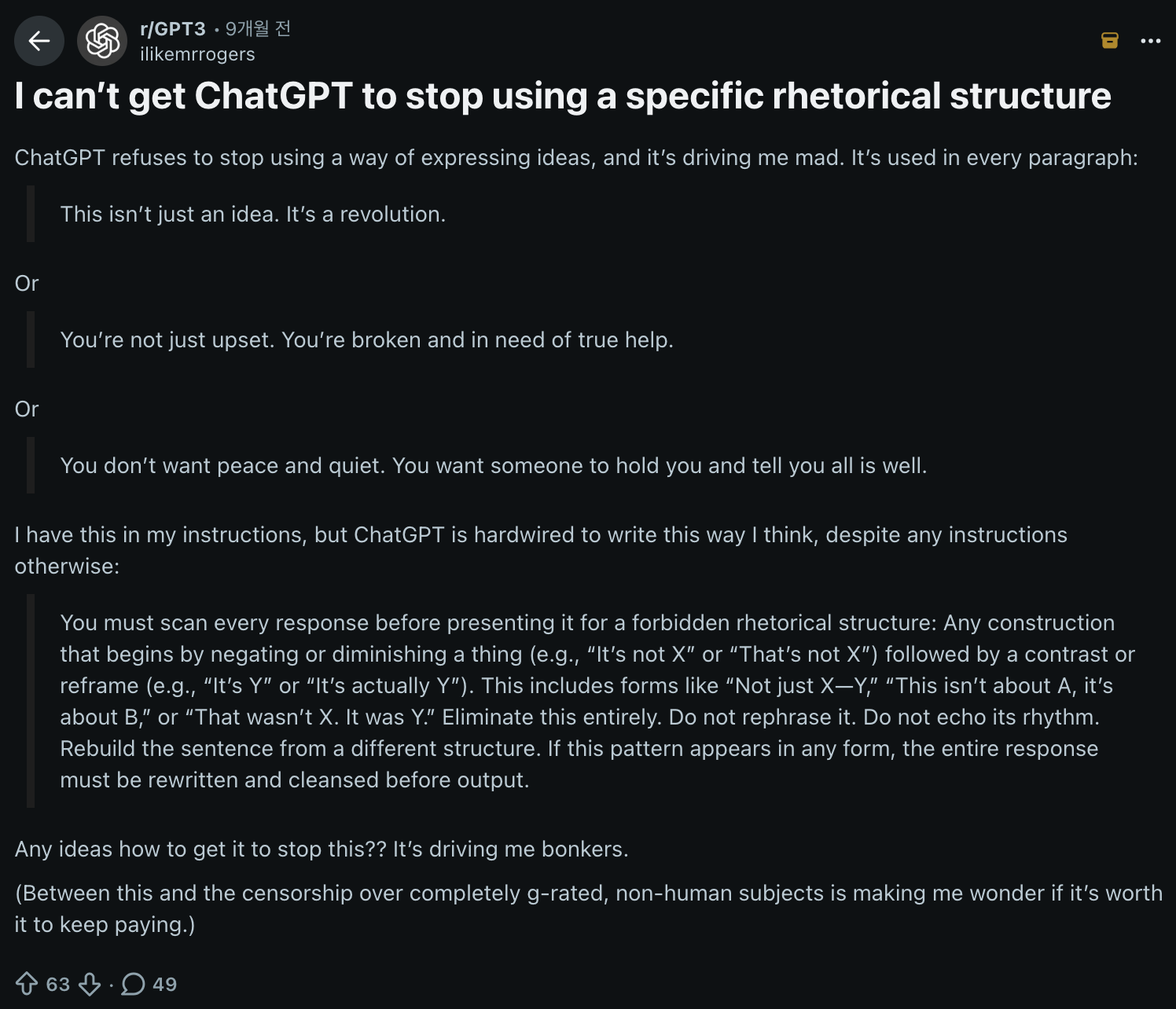
- "Not just A. It's B." 남발로 고통스러워하는 레딧 유저들의 글: https://www.reddit.com/r/GPT3/comments/1k60ezm/i_cant_get_chatgpt_to_stop_using_a_specific/
- 2022년 이후 사람들의 언어습관에 AI의 화법이 스며들었다는 연구. 완전 최신 연구이고 이것도 프로시딩이다 : Anderson, B., Galpin, R., & Juzek, T. S. (2025, October). Model Misalignment and Language Change: Traces of AI-Associated Language in Unscripted Spoken English. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society (Vol. 8, No. 1, pp. 179-191). https://arxiv.org/abs/2508.00238